Python Scrapy 库
Scrapy 是一个功能强大的 Python 爬虫框架,专门用于抓取网页数据并提取信息。
Scrapy常被用于数据挖掘、信息处理或存储历史数据等应用。
Scrapy 内置了许多有用的功能,如处理请求、跟踪状态、处理错误、处理请求频率限制等,非常适合进行高效、分布式的网页爬取。
与简单的爬虫库(如 requests 和 BeautifulSoup)不同,Scrapy 是一个全功能的爬虫框架,具有高度的可扩展性和灵活性,适用于复杂和大规模的网页抓取任务。
Scrapy 官网:https://scrapy.org/。
Scrapy 特点与介绍:https://www.runoob.com/w3cnote/scrapy-detail.html。
Scrapy 架构图(绿线是数据流向):
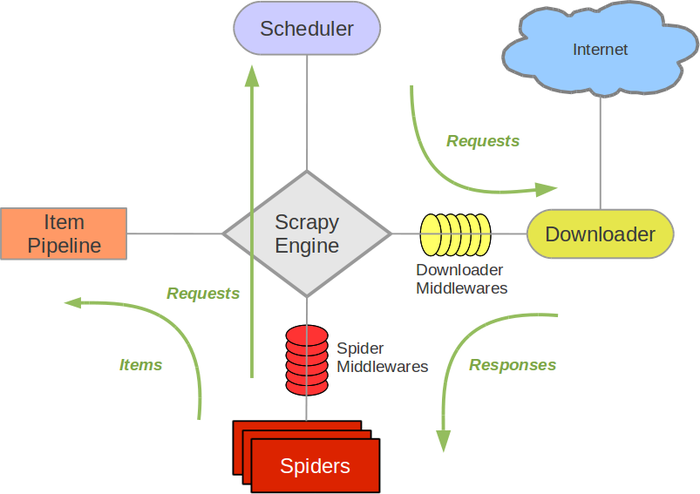
Scrapy 的工作基于以下几个核心组件:
- Spider:爬虫类,用于定义如何从网页中提取数据以及如何跟踪网页的链接。
- Item:用来定义和存储抓取的数据。相当于数据模型。
- Pipeline:用于处理抓取到的数据,常用于清洗、存储数据等操作。
- Middleware:用来处理请求和响应,可以用于设置代理、处理 cookies、用户代理等。
- Settings:用来配置 Scrapy 项目的各项设置,如请求延迟、并发请求数等。
安装 Scrapy
在使用 Scrapy 之前,你需要先安装它,我们使用 pip 安装:
pip install scrapy
Scrapy 项目结构
Scrapy 项目是一个结构化的目录,其中包含多个文件夹和模块,旨在帮助你组织爬虫的代码。
Scrapy 使用命令行工具来创建和管理爬虫项目。你可以使用以下命令创建一个新的 Scrapy 项目:
scrapy startproject myproject
这将创建一个名为 myproject 的项目,项目结构大致如下:
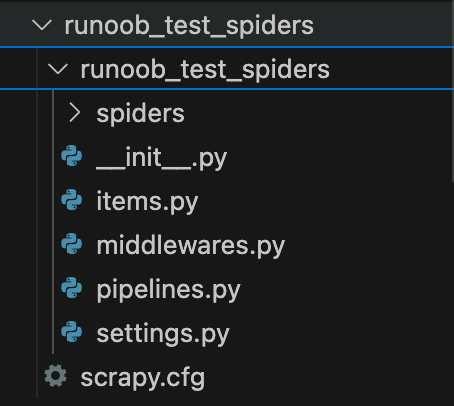
myproject/
scrapy.cfg # 项目的配置文件
myproject/ # 项目源代码文件夹
__init__.py
items.py # 定义抓取的数据结构
middlewares.py # 定义中间件
pipelines.py # 定义数据处理管道
settings.py # 项目的设置文件
spiders/ # 存放爬虫代码的文件夹
__init__.py
myspider.py # 自定义的爬虫代码
编写一个简单的 Scrapy 爬虫
以下是一个基本的 Scrapy 爬虫示例,展示了如何从网页中抓取数据。
我们创建一个爬虫项目:
scrapy startproject runoob_test_spiders
执行以上命令,如果成功会输出:
templates/project', created in:/Users/Runoob/runoob-test/runoob_test_spiders
You can start your first spider with:
cd runoob_test_spiders
scrapy genspider example example.com
生成的项目结构如下:
然后进入该目录:
cd runoob_test_spiders
接下来通过 scrapy genspider 命令来创建一个爬虫:
scrapy genspider douban_spider movie.douban.com
目录结构如下:
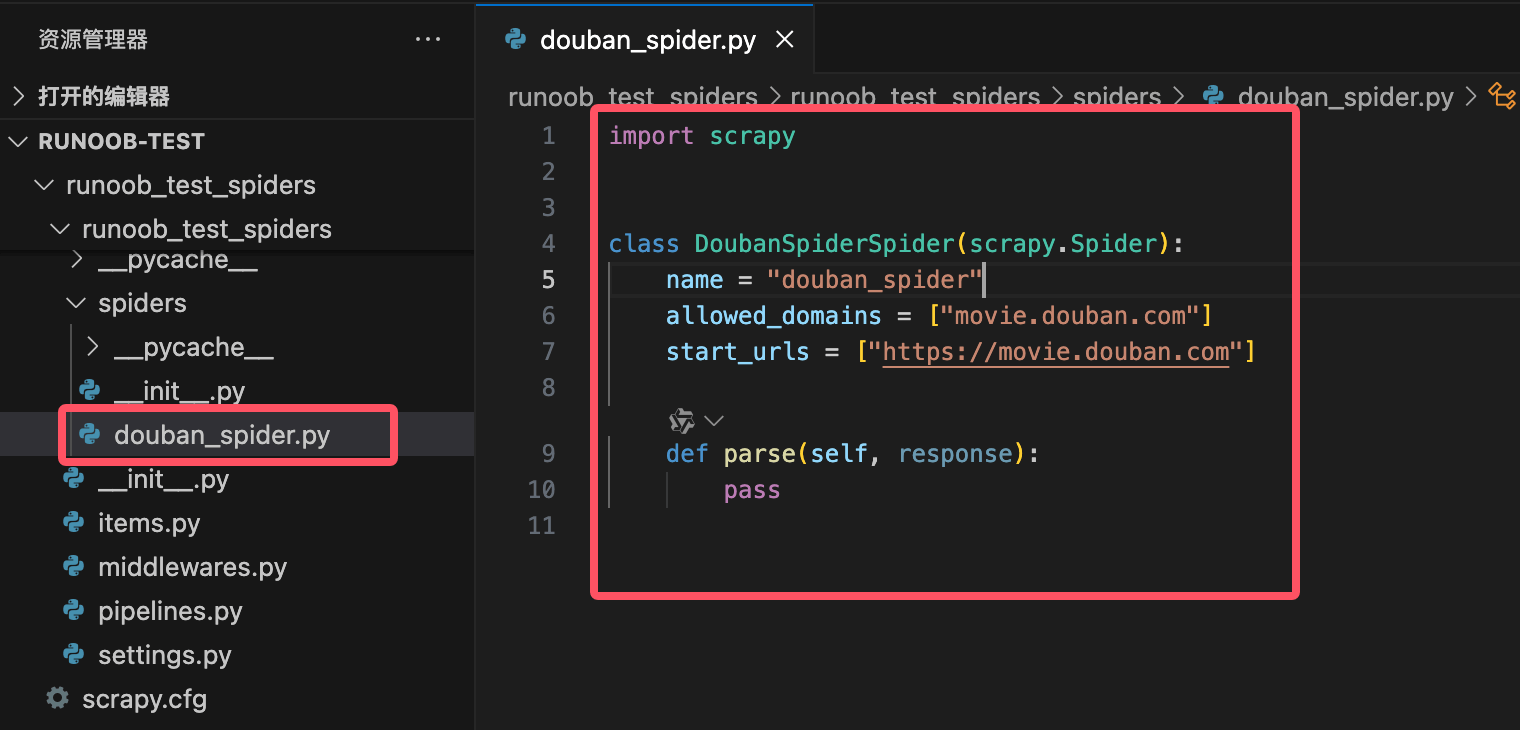
runoob_test_spiders 目录下生成一个名为 douban_spider.py 的文件,代码如下:
实例
class DoubanSpiderSpider(scrapy.Spider):
name = "douban_spider"
allowed_domains = ["movie.douban.com"]
start_urls = ["https://movie.douban.com"]
def parse(self, response):
pass
代码说明:
name:定义爬虫的名称,必须是唯一的。allowed_domains:限制爬虫的访问域名,防止爬虫爬取其他域名的网页。start_urls:定义爬虫的起始页面,爬虫将从这些页面开始抓取。parse:parse方法是每个爬虫的核心部分,用于处理响应并提取数据。它接收一个response对象,表示服务器返回的页面内容。
编写爬虫代码
编写爬虫代码前我们需要注意几个点:
- 豆瓣等网站可能会检测爬虫行为,建议设置 USER_AGENT 和 DOWNLOAD_DELAY 来模拟正常用户行为。
- 在爬取数据时,请遵守目标网站的 robots.txt 文件规定,避免对服务器造成过大压力。
- 如果频繁爬取,可能会触发 IP 封禁。
修改 settings.py 配置
在 settings.py 中添加以下配置,以模拟浏览器请求并绕过反爬虫机制:
# 设置 User-Agent USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' # 不遵守 robots.txt 规则 ROBOTSTXT_OBEY = False # 设置下载延迟,避免过快请求 DOWNLOAD_DELAY = 2 # 启用自动限速扩展 AUTOTHROTTLE_ENABLED = True AUTOTHROTTLE_START_DELAY = 2 AUTOTHROTTLE_MAX_DELAY = 5
在爬虫代码中,添加自定义请求头(如 User-Agent 和 Referer),以进一步模拟浏览器行为。
打开 douban_spider.py 文件,并修改其内容如下:
实例
class DoubanSpider(scrapy.Spider):
name = "douban_spider"
start_urls = [
'https://movie.douban.com/top250',
]
def start_requests(self):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'https://movie.douban.com/',
}
for url in self.start_urls:
yield scrapy.Request(url, headers=headers, callback=self.parse)
def parse(self, response):
for movie in response.css('div.item'):
yield {
'title': movie.css('span.title::text').get(),
'rating': movie.css('span.rating_num::text').get(),
'quote': movie.css('span.inq::text').get(),
}
# 处理分页
next_page = response.css('span.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
代码解析:
name = "douban_spider": 定义爬虫的名称。start_urls: 定义爬虫开始爬取的初始 URL(豆瓣电影 Top 250 页面)。parse方法:使用 CSS 选择器提取每部电影的标题、评分和简介。
span.title::text:提取电影标题。span.rating_num::text:提取电影评分。span.inq::text:提取电影简介。
分页处理:
使用
span.next a::attr(href)提取下一页的链接。如果存在下一页,使用
response.follow继续爬取。
在命令行中运行以下命令来启动爬虫:
scrapy crawl douban_spider -o douban_movies.csv
这将启动爬虫并将提取的数据保存到 douban_movies.csv 文件中。
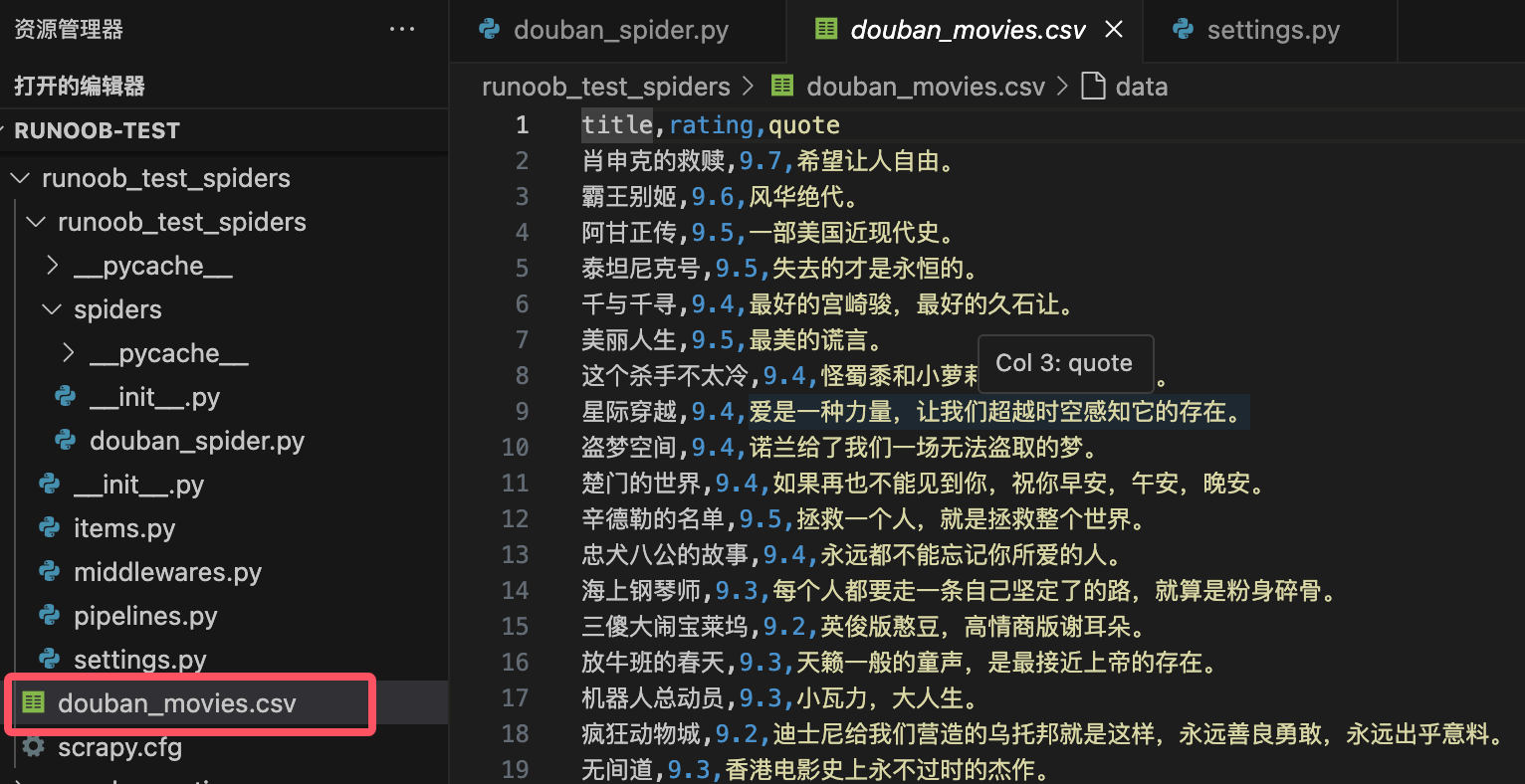
注意:以上内容仅供学习,在爬取数据时,请遵守目标网站的 robots.txt 文件规定。
常用方法
1. 爬虫方法
| 方法名 | 作用描述 | 示例 |
|---|---|---|
start_requests() |
生成初始请求,可以自定义请求头、请求方法等。 | yield scrapy.Request(url, callback=self.parse) |
parse(response) |
处理响应并提取数据,是爬虫的核心方法。 | yield {'title': response.css('h1::text').get()} |
follow(url, callback) |
自动处理相对 URL 并生成新的请求,用于分页或链接跳转。 | yield response.follow(next_page, callback=self.parse) |
closed(reason) |
爬虫关闭时调用,用于清理资源或记录日志。 | def closed(self, reason): print('Spider closed:', reason) |
log(message) |
记录日志信息。 | self.log('This is a log message') |
2. 数据提取方法
| 方法名 | 作用描述 | 示例 |
|---|---|---|
response.css(selector) |
使用 CSS 选择器提取数据。 | title = response.css('h1::text').get() |
response.xpath(selector) |
使用 XPath 选择器提取数据。 | title = response.xpath('//h1/text()').get() |
get() |
从 SelectorList 中提取第一个匹配的结果(字符串)。 |
title = response.css('h1::text').get() |
getall() |
从 SelectorList 中提取所有匹配的结果(列表)。 |
titles = response.css('h1::text').getall() |
attrib |
提取当前节点的属性。 | link = response.css('a::attr(href)').get() |
3. 请求与响应方法
| 方法名 | 作用描述 | 示例 |
|---|---|---|
scrapy.Request(url, callback, method, headers, meta) |
创建一个新的请求。 | yield scrapy.Request(url, callback=self.parse, headers=headers) |
response.url |
获取当前响应的 URL。 | current_url = response.url |
response.status |
获取响应的状态码。 | if response.status == 200: print('Success') |
response.meta |
获取请求中传递的额外数据。 | value = response.meta.get('key') |
response.headers |
获取响应的头信息。 | content_type = response.headers.get('Content-Type') |
4. 中间件与管道方法
| 方法名 | 作用描述 | 示例 |
|---|---|---|
process_request(request, spider) |
在请求发送前处理请求(下载器中间件)。 | request.headers['User-Agent'] = 'Mozilla/5.0' |
process_response(request, response, spider) |
在响应返回后处理响应(下载器中间件)。 | if response.status == 403: return request.replace(dont_filter=True) |
process_item(item, spider) |
处理提取的数据(管道)。 | if item['price'] < 0: raise DropItem('Invalid price') |
open_spider(spider) |
爬虫启动时调用(管道)。 | def open_spider(self, spider): self.file = open('items.json', 'w') |
close_spider(spider) |
爬虫关闭时调用(管道)。 | def close_spider(self, spider): self.file.close() |
5. 工具与扩展方法
| 方法名 | 作用描述 | 示例 |
|---|---|---|
scrapy shell |
启动交互式 Shell,用于调试和测试选择器。 | scrapy shell 'http://example.com' |
scrapy crawl <spider_name> |
运行指定的爬虫。 | scrapy crawl myspider -o output.json |
scrapy check |
检查爬虫代码的正确性。 | scrapy check |
scrapy fetch |
下载指定 URL 的内容。 | scrapy fetch 'http://example.com' |
scrapy view |
在浏览器中查看 Scrapy 下载的页面。 | scrapy view 'http://example.com' |
6. 常用设置(settings.py)
| 设置项 | 作用描述 | 示例 |
|---|---|---|
USER_AGENT |
设置请求头中的 User-Agent。 | USER_AGENT = 'Mozilla/5.0' |
ROBOTSTXT_OBEY |
是否遵守 robots.txt 规则。 |
ROBOTSTXT_OBEY = False |
DOWNLOAD_DELAY |
设置下载延迟,避免过快请求。 | DOWNLOAD_DELAY = 2 |
CONCURRENT_REQUESTS |
设置并发请求数。 | CONCURRENT_REQUESTS = 16 |
ITEM_PIPELINES |
启用管道。 | ITEM_PIPELINES = {'myproject.pipelines.MyPipeline': 300} |
AUTOTHROTTLE_ENABLED |
启用自动限速扩展。 | AUTOTHROTTLE_ENABLED = True |
7. 其他常用方法
| 方法名 | 作用描述 | 示例 |
|---|---|---|
response.follow_all(links, callback) |
批量处理链接并生成请求。 | yield from response.follow_all(links, callback=self.parse) |
response.json() |
将响应内容解析为 JSON 格式。 | data = response.json() |
response.text |
获取响应的文本内容。 | html = response.text |
response.selector |
获取响应内容的 Selector 对象。 |
title = response.selector.css('h1::text').get() |
以上表格列出了 Scrapy 中常用的方法及其作用。这些方法涵盖了爬虫开发的各个方面,包括请求生成、数据提取、中间件处理、管道操作等。通过掌握这些方法,你可以高效地编写和管理 Scrapy 爬虫。如果需要更详细的功能,可以参考 Scrapy 官方文档。
方法使用举例
1. start_requests()
start_requests() 方法是 Scrapy 爬虫的入口点,用于生成初始请求。通常在这个方法中定义爬虫的起始 URL。
实例
class MySpider(scrapy.Spider):
name = 'myspider'
def start_requests(self):
urls = [
'http://example.com/page1',
'http://example.com/page2',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
2. parse()
parse() 方法是默认的响应处理方法,用于解析响应并提取数据或生成新的请求。
实例
# 提取页面标题
title = response.css('title::text').get()
yield {
'title': title
}
3. parse_item()
parse_item() 方法用于解析单个项目(Item)的响应,通常用于提取结构化数据。
实例
item = {}
item['name'] = response.css('div.name::text').get()
item['price'] = response.css('div.price::text').get()
yield item
4. follow()
follow() 方法用于生成新的请求并自动处理响应,通常用于跟踪链接。
实例
for link in response.css('a::attr(href)'):
yield response.follow(link, self.parse_item)
5. yield
yield 关键字用于生成请求或项目(Item),并将其传递给 Scrapy 引擎进行处理。
实例
yield {
'title': response.css('title::text').get()
}
6. Item
Item 类用于定义数据结构,通常用于存储从网页中提取的数据。
实例
class MyItem(scrapy.Item):
name = scrapy.Field()
price = scrapy.Field()
7. ItemLoader
ItemLoader 类用于加载和填充 Item 对象,简化数据提取和处理的流程。
实例
from myproject.items import MyItem
def parse(self, response):
loader = ItemLoader(item=MyItem(), response=response)
loader.add_css('name', 'div.name::text')
loader.add_css('price', 'div.price::text')
yield loader.load_item()
8. Request
Request 类用于生成 HTTP 请求对象,通常用于定义请求的 URL、回调方法等。
实例
def parse(self, response):
yield scrapy.Request(url='http://example.com/page3', callback=self.parse_item)
9. Response
Response 类表示 HTTP 响应对象,包含从服务器返回的 HTML 内容、状态码等信息。
实例
print(response.status) # 打印响应状态码
print(response.body) # 打印响应内容
10. Selector
Selector 类用于从 HTML 或 XML 文档中提取数据,支持 XPath 和 CSS 选择器。
实例
title = response.xpath('//title/text()').get()
yield {
'title': title
}
11. CrawlSpider
CrawlSpider 是一种特殊的 Spider 类,用于处理复杂的爬取规则和链接跟踪。
实例
from scrapy.linkextractors import LinkExtractor
class MyCrawlSpider(CrawlSpider):
name = 'mycrawlspider'
allowed_domains = ['example.com']
start_urls = ['http://example.com']
rules = (
Rule(LinkExtractor(allow=('page/\d+',)), callback='parse_item'),
)
def parse_item(self, response):
yield {
'title': response.css('title::text').get()
}
12. LinkExtractor
LinkExtractor 类用于从响应中提取链接,通常用于自动跟踪页面中的链接。
实例
def parse(self, response):
extractor = LinkExtractor(allow=('page/\d+',))
links = extractor.extract_links(response)
for link in links:
yield scrapy.Request(link.url, callback=self.parse_item)
13. Pipeline
Pipeline 类用于处理爬取到的数据,通常用于数据清洗、存储等操作。
实例
def process_item(self, item, spider):
# 处理 item 数据
return item
14. Middleware
Middleware 类用于处理请求和响应的中间件,通常用于修改请求头、处理异常等操作。
实例
def process_request(self, request, spider):
# 修改请求头
request.headers['User-Agent'] = 'MyCustomUserAgent'
return None

点我分享笔记