Sklearn 机器学习模型
机器学习模型是实现自动化数据分析、模式识别和预测的核心工具。
根据任务的不同,机器学习模型可以分为分类模型、回归模型和聚类模型等。
本章节将详细介绍这些常见的机器学习模型,并介绍如何评估和优化模型。
1、分类模型
分类问题是机器学习中最常见的问题之一,其目的是将输入数据映射到离散的类别标签。
常见的分类模型有逻辑回归、K-近邻、支持向量机、决策树和随机森林等。逻辑回归(Logistic Regression)
逻辑回归是一种经典的线性分类模型,虽然名字中有"回归",但它实际上用于二分类问题。它通过将线性回归的输出通过逻辑函数(sigmoid)映射到 0 和 1 之间,从而预测事件的概率。
逻辑回归的核心公式为:

scikit-learn 实现:
实例
from sklearn.model_selection import train_test_split
# 假设 X 是特征矩阵,y 是标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model = LogisticRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
K-近邻(K-Nearest Neighbors, KNN)
K-近邻(KNN)是一种基于实例的学习方法,预测时通过计算待预测样本与训练集中所有样本的距离,选取距离最近的 K 个邻居,并根据邻居的标签进行预测。
主要参数:
- K:选择的邻居数量。
- 距离度量:常用欧氏距离,也可以使用曼哈顿距离、闵可夫斯基距离等。
scikit-learn 实现:
实例
from sklearn.model_selection import train_test_split
# 假设 X 是特征矩阵,y 是标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model = KNeighborsClassifier(n_neighbors=3)
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
支持向量机(Support Vector Machine, SVM)
支持向量机是一种强大的分类模型,尤其适用于高维数据。
SVM 的基本思想是找到一个超平面,使得不同类别的样本点之间的间隔最大化。对于非线性可分的数据,SVM 通过核技巧将数据映射到高维空间,找到一个分隔超平面。
核函数:
- 线性核:适用于线性可分的数据。
- 高斯径向基核(RBF):适用于非线性数据。
- 多项式核:适用于具有多项式关系的数据。
scikit-learn 实现:
实例
from sklearn.model_selection import train_test_split
# 假设 X 是特征矩阵,y 是标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model = SVC(kernel='linear') # 使用线性核
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
决策树与随机森林(Decision Tree & Random Forest)
决策树是一种树形结构的分类模型,通过对数据进行分裂,最终将数据划分到不同的类别。随机森林则是通过构建多棵决策树,并通过投票或平均来决定最终的预测结果。
决策树通过选择最优的特征进行数据划分,选择准则通常是 信息增益 或 基尼系数。
随机森林通过多棵决策树的集成来减少过拟合,并提高模型的准确性。它通过引入随机性(如随机选择特征、随机选择数据子集)来增加模型的多样性。
scikit-learn 实现:
实例
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# 假设 X 是特征矩阵,y 是标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 决策树
dt_model = DecisionTreeClassifier()
dt_model.fit(X_train, y_train)
# 随机森林
rf_model = RandomForestClassifier(n_estimators=100)
rf_model.fit(X_train, y_train)
# 预测
dt_pred = dt_model.predict(X_test)
rf_pred = rf_model.predict(X_test)
2、回归模型
回归问题的目标是预测一个连续的输出变量。常见的回归模型包括线性回归、岭回归和 Lasso 回归。
线性回归(Linear Regression)
线性回归通过拟合一条直线来预测目标变量。其核心假设是特征与目标变量之间存在线性关系。
对于一个简单的线性回归问题,模型可以表示为:
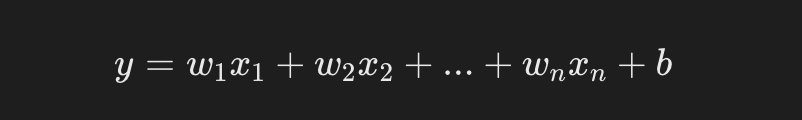
- y 是预测值(目标值)。
- x1,x2,xn 是输入特征。
- w1,w2,wn是待学习的权重(模型参数)。
- b 是偏置项。
scikit-learn 实现:
实例
from sklearn.model_selection import train_test_split
# 假设 X 是特征矩阵,y 是目标变量
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
岭回归(Ridge Regression)
岭回归是线性回归的一个变种,使用 L2 正则化 来约束模型的复杂度,避免过拟合。通过惩罚回归系数的大小,岭回归能更好地处理多重共线性问题。
scikit-learn 实现:
实例
model = Ridge(alpha=1.0) # alpha 是正则化参数
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
Lasso 回归(Lasso Regression)
Lasso 回归也是线性回归的一种形式,它使用 L1 正则化 来对回归系数进行惩罚。与岭回归不同,Lasso 会将一些回归系数压缩到零,从而实现特征选择。
scikit-learn 实现:
实例
model = Lasso(alpha=0.1) # alpha 是正则化参数
model.fit(X_train, y_train)
# 预测
y_pred = model.predict(X_test)
3、聚类模型
聚类是一种无监督学习方法,其目标是将数据集中的对象分为不同的组(或簇),使得同一簇中的对象尽可能相似,而不同簇之间的对象尽可能不同。
K-均值(K-Means)
K-均值是一种常见的聚类算法,目标是将数据分为 K 个簇,通过最小化每个数据点与其簇中心的距离来优化簇划分。
scikit-learn 实现:
实例
# 假设 X 是特征矩阵
model = KMeans(n_clusters=3)
model.fit(X)
# 获取聚类标签
labels = model.predict(X)
DBSCAN(密度聚类)
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,它通过寻找密度相对较高的区域来进行聚类,不需要事先指定簇的数量。
scikit-learn 实现:
实例
# 假设 X 是特征矩阵
model = DBSCAN(eps=0.5, min_samples=5)
model.fit(X)
# 获取聚类标签
labels = model.labels_
层次聚类(Hierarchical Clustering)
层次聚类是一种通过递归地合并或分割簇的方式进行聚类的方法。常用的层次聚类方法有 凝聚型聚类(Agglomerative)和 分裂型聚类(Divisive)。
scikit-learn 实现:
实例
# 假设 X 是特征矩阵
model = AgglomerativeClustering(n_clusters=3)
labels = model.fit_predict(X)
4、模型评估与选择
精度、召回率、F1 分数
在分类问题中,常用的评估指标有 精度(Accuracy)、召回率(Recall) 和 F1 分数(F1 Score)。这些指标帮助我们了解模型的性能。
- 精度:所有正确预测的比例。
- 召回率:正确预测的正例占所有实际正例的比例。
- F1 分数:精度和召回率的调和平均数。
scikit-learn 实现:
实例
accuracy = accuracy_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
print(f"Recall: {recall}")
print(f"F1 Score: {f1}")
交叉验证(cross_val_score)
交叉验证是一种用于评估模型性能的技术,它将数据集划分为多个子集,并多次训练和测试模型,从而获得更加稳定的性能评估。
scikit-learn 实现:
实例
from sklearn.linear_model import LogisticRegression
# 假设 X 是特征矩阵,y 是标签
model = LogisticRegression()
# 进行 5 折交叉验证
scores = cross_val_score(model, X, y, cv=5)
print(f"Cross-validation scores: {scores}")
网格搜索(GridSearchCV)
网格搜索是一种用于模型超参数调优的方法,它通过穷举搜索指定参数空间的所有可能组合,找出最佳的参数配置。
scikit-learn 实现:
实例
from sklearn.svm import SVC
# 假设 X 是特征矩阵,y 是标签
parameters = {'kernel': ['linear', 'rbf'], 'C': [1, 10, 100]}
model = SVC()
# 网格搜索
grid_search = GridSearchCV(model, parameters, cv=5)
grid_search.fit(X, y)
# 输出最佳参数
print(f"Best parameters: {grid_search.best_params_}")

点我分享笔记