机器学习如何工作
机器学习(Machine Learning, ML)的核心思想是让计算机能够通过数据学习,并从中推断出规律或模式,而不依赖于显式编写的规则或代码。
简单来说,机器学习的工作流程是让机器通过历史数据自动改进其决策和预测能力。
机器学习的工作流程可以简化为以下几个步骤:
- 收集数据:准备包含特征和标签的数据。
- 选择模型:根据任务选择合适的机器学习算法。
- 训练模型:让模型通过数据学习模式,最小化误差。
- 评估与验证:通过测试集评估模型性能,并进行优化。
- 部署模型:将训练好的模型应用到实际场景中进行预测。
- 持续改进:随着新数据的产生,模型需要定期更新和优化。
这个过程能够让计算机从经验中自动学习,并在各种任务中做出越来越准确的预测。
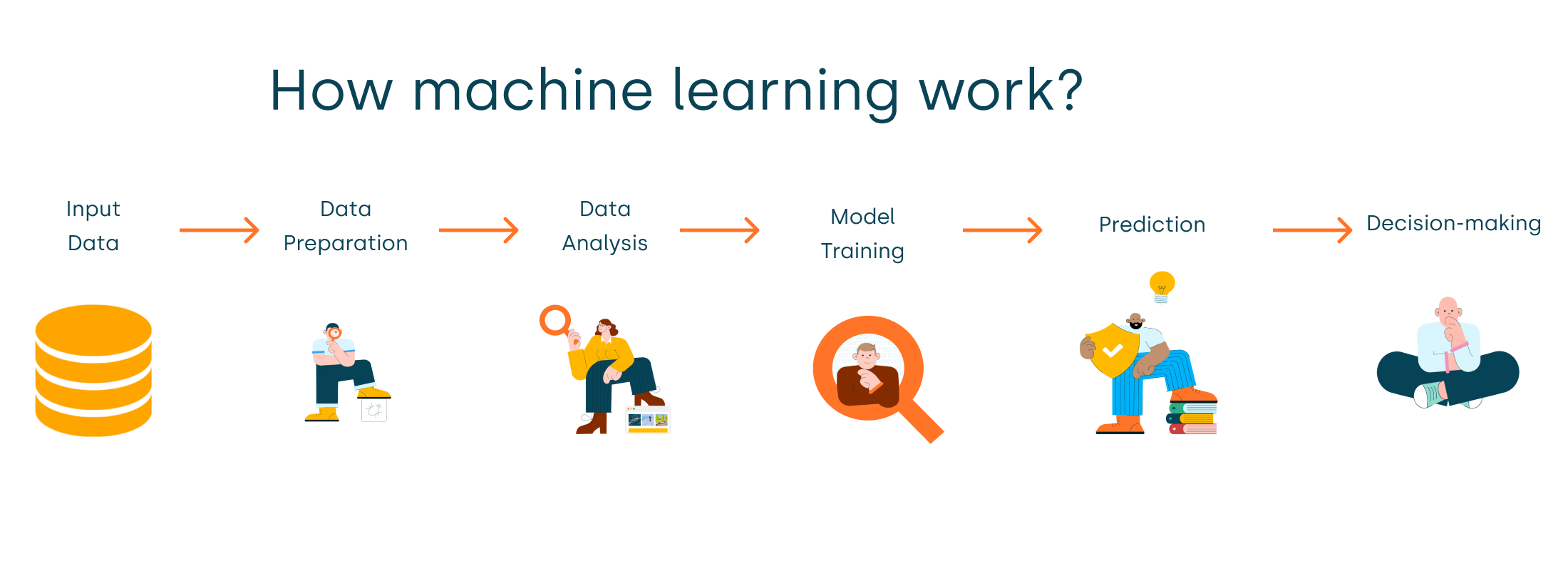
我们可以从以下几个方面来理解机器学习是如何工作的:
1. 数据输入:数据是学习的基础
机器学习的第一步是数据收集。没有数据,机器学习模型无法进行训练。数据通常包括"输入特征"和"标签":
-
输入特征(Features): 这些是模型用来做预测或分类的信息。例如,在房价预测问题中,输入特征可以是房子的面积、地理位置、卧室数量等。
-
标签(Labels): 标签是我们想要预测或分类的结果,通常是一个数字或类别。例如,在房价预测问题中,标签是房子的价格。
机器学习模型的目标是从数据中找出输入特征与标签之间的关系,基于这些关系做出预测。
2. 模型选择:选择合适的学习算法
机器学习模型(也叫做算法)是帮助计算机学习数据并进行预测的工具。根据数据的性质和任务的不同,常见的机器学习模型包括:
-
监督学习模型: 给定带有标签的数据,模型通过学习输入和标签之间的关系来做预测。例如,线性回归、逻辑回归、支持向量机(SVM) 和 决策树。
-
无监督学习模型: 没有标签的数据,模型通过探索数据中的结构或模式来进行学习。例如,K-means 聚类、主成分分析(PCA)。
-
强化学习模型: 模型在与环境互动的过程中,通过奖励和惩罚来学习最佳行为。例如,Q-learning、深度强化学习(Deep Q-Networks, DQN)。
3. 训练过程:让模型从数据中学习
在训练阶段,模型通过历史数据"学习"输入和标签之间的关系,通常通过最小化一个损失函数(Loss Function)来优化模型的参数。训练过程可以概括为以下步骤:
-
初始状态: 模型从随机值开始。比如,神经网络的权重是随机初始化的。
-
计算预测: 对于每个输入,模型会做出一个预测。这是通过将输入数据传递给模型,计算得到输出。
-
计算误差(损失): 误差是指模型预测的输出与实际标签之间的差异。例如,对于回归问题,误差可以通过均方误差(MSE)来衡量。
-
优化模型: 通过反向传播(在神经网络中)或梯度下降等优化算法,不断调整模型的参数(如神经网络的权重),使得误差最小化。这个过程就是训练,直到模型能够在训练数据上做出比较准确的预测。
4. 验证与评估:测试模型的性能
训练过程完成后,我们需要评估模型的性能。为了避免模型过度拟合训练数据,我们将数据分为训练集和测试集,其中:
- 训练集: 用于训练模型的部分数据。
- 测试集: 用于评估模型性能的部分数据,通常不参与训练过程。
常见的评估指标包括:
- 准确率(Accuracy): 分类问题中正确分类的比例。
- 均方误差(MSE): 回归问题中,预测值与真实值差的平方的平均值。
- 精确率(Precision)与召回率(Recall): 用于二分类问题,尤其是类别不平衡时。
- F1分数: 精确率与召回率的调和平均数,综合考虑分类器的表现。
5. 优化与调整:提高模型的精度
如果模型在测试集上的表现不理想,可能需要进一步优化。这通常包括:
-
调整超参数(Hyperparameters): 比如学习率、正则化系数、树的深度等。这些超参数影响模型的学习能力。
-
模型选择与融合: 尝试不同的模型或模型融合(比如集成学习方法,如随机森林、XGBoost 等)来提高精度。
-
数据增强: 扩展训练数据集,比如对图像进行旋转、翻转等操作,帮助模型提高泛化能力。
6. 模型部署与预测:实际应用
一旦模型在训练和测试数据上表现良好,就可以将模型部署到实际应用中:
-
模型部署: 将训练好的模型嵌入到应用程序、网站、服务器等系统中,供用户使用。
-
实时预测: 在实际环境中,新的数据输入到模型中,模型根据之前学习到的模式进行实时预测或分类。
7. 持续学习与模型更新:
机器学习系统通常不是一次性完成的。在实际应用中,随着时间的推移,新的数据会不断产生,因此,模型需要定期更新和再训练,以保持其预测能力。这可以通过在线学习、迁移学习等方法来实现。

点我分享笔记